A Record Year and What We Learned About AI, Markets, and the Future of Forecasting
 It’s been a challenging year. Public imagination has been captured by prediction markets and AI alike as potential oracles for, well, everything. And yet, here we are at Good Judgment Inc, not just standing but setting records.
It’s been a challenging year. Public imagination has been captured by prediction markets and AI alike as potential oracles for, well, everything. And yet, here we are at Good Judgment Inc, not just standing but setting records.
This year, Good Judgment launched an unprecedented 1,140 forecasting questions across our public and private platforms, with a void rate of exactly zero. That’s a benchmark other forecasting platforms cannot claim.
Our top-line developments in 2025:
- Our Superforecasters have continued to outperform the markets, as featured in the Financial Times, and provide precise probabilities in our 11th annual collaboration with The Economist.
- Good Judgment won an Honourable Mention in the 2025 IF Awards from the Association of Professional Futurists (APF) together with our UK partners ForgeFront for our joint Future.Ctrl methodology. This is a much-coveted professional award in the foresight industry.
- Good Judgment’s CEO Dr. Warren Hatch delivered a keynote address at UN OCHA’s Global Humanitarian Policy Forum. We find it especially heartwarming that global leaders at the top level are paying attention to Superforecasting as a way to improve decision-making.
- We have added an executive education program to our Superforecasting Workshops menu. It’s designed for decision-makers who want to incorporate probability forecasts into their process. So far, our client list includes a major technology company, an oil multinational, and investment funds, among others.
- We now offer in-person workshops as part of a leadership development program with our Canadian partner, Kingbridge Centre.
But beyond the big names and numbers, we’ve learned something important about where human forecasting fits in an increasingly automated world.
The Two-Front Challenge
On one side, prediction markets like Polymarket have drawn enormous attention. On the other, large language models (LLMs) have shown remarkable ability to synthesize information and generate plausible-sounding forecasts. So are Superforecasters still the best in the field? Are we still needed?
Our answer, backed by data, is yes.
Outperforming the Markets
For the third year in a row, our US Federal Reserve forecasts beat the CME’s FedWatch tool, a result we’ve been documenting throughout the year and that was featured in the Financial Times. Three years is a pattern.
What about Polymarket? On questions like Fed rate decisions, we find it essentially duplicates FedWatch, volatility included. In other words, the prediction market hype hasn’t translated into better forecasts on questions like these, and these are the type of questions that matter most to our clients.
The AI Question
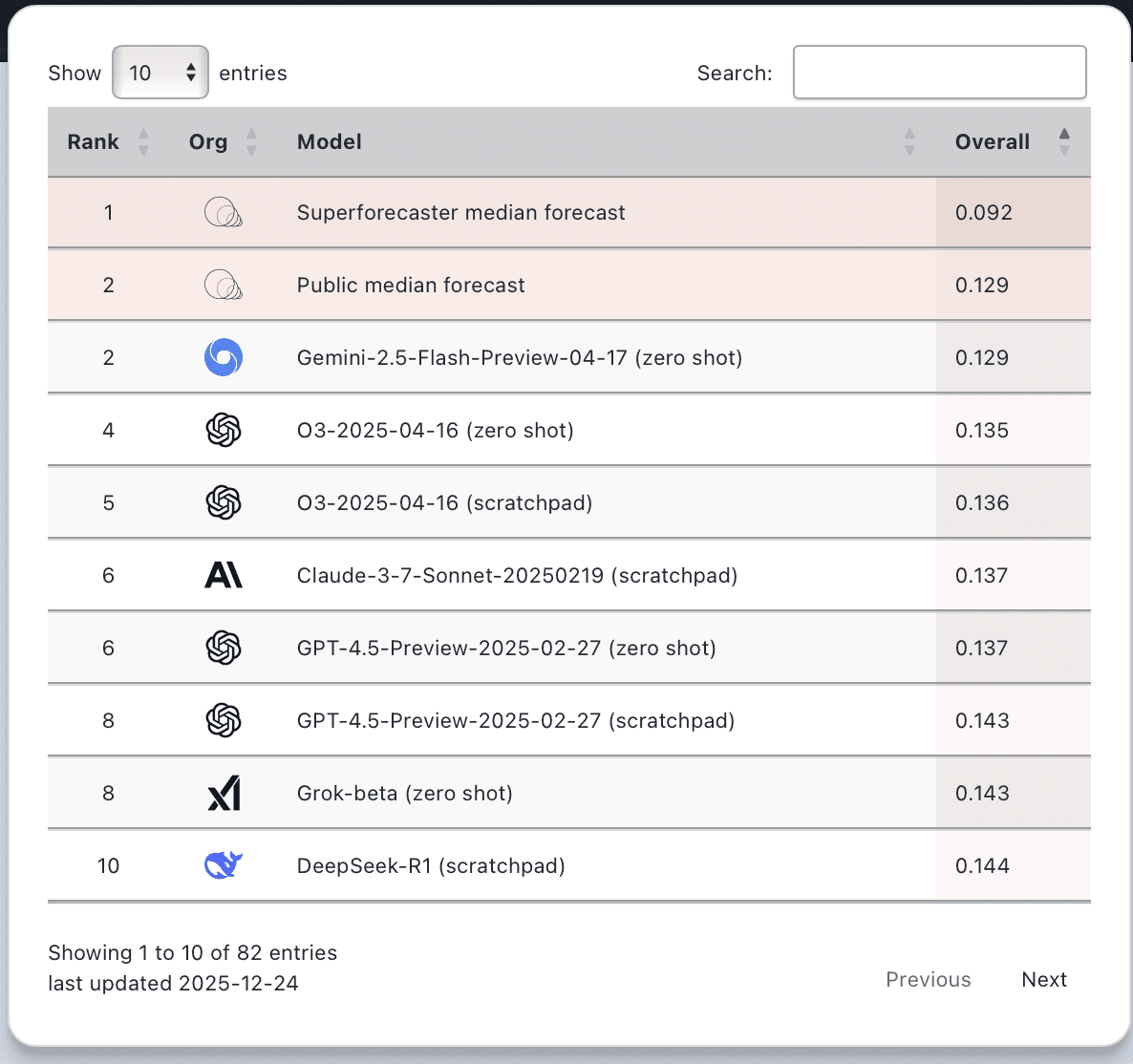 Forecasting Research Institute, our sibling organization, runs the only forecasting competition we know that directly pits humans against AI models. According to their latest results, the best-performing LLM still lags the best human forecasters by 40%.
Forecasting Research Institute, our sibling organization, runs the only forecasting competition we know that directly pits humans against AI models. According to their latest results, the best-performing LLM still lags the best human forecasters by 40%.
Why the gap? It comes down to a fundamental difference in what forecasters do best versus what AI does best.
AI synthesizes existing information. If the answer to a question is somewhere on the internet, a well-trained model will surface it quickly. But for questions marked with greater volatility (who wins the next election, where markets are heading, what happens next in a geopolitical crisis), the answer isn’t sitting in a database. It’s contingent on human behavior, a much harder variable to predict than mere extrapolation from data.
The best human forecasters go a step or two beyond the retrieval and synthesis of information. They weigh evidence, model uncertainty, update their thinking as conditions change, and produce nuanced judgments. That’s a capability AI could tap into only by accessing Superforecasters’ aggregated forecasts and their detailed reasoning. As we’ve written elsewhere, “What our clients value are not only the numbers but also the rationales that Superforecasters provide with their numerical forecasts. By examining their chain of reasoning—something that black-box systems cannot provide reliably—leaders are able to scrutinize assumptions, trace causal links, and stress-test scenarios by noting hidden risks.” For the types of questions we see in our client work, Superforecasters are still the best.
Looking Ahead
None of this means we’re ignoring AI developments. Quite the opposite. We’ve been actively experimenting with how to integrate AI into the Superforecasting process. It is Good Judgment’s opinion that a hybrid approach is the path forward. Not AI replacing Superforecasters, but AI amplifying what Superforecasters already do well.
As we head into the new year, we are seeing momentum picking up once again on the business side. FutureFirst™, our subscription-based forecast monitoring tool, has seen all Q4 renewals go through. Once organizations experience what our structured forecasting provides and build it into their workflows, they tend to stay.
On the training side, we are now offering Advanced Judgment & Modeling, the next-level Superforecasting training to graduates of our two-day workshop. As a Texas National Security Review study found, decision-makers tend to be vasty overconfident but can improve calibration even with brief training. Our analysis supports these findings.
Our public workshop continued to receive stellar ratings from participants in 2025. Here’s an excerpt from one of our favorite reviews:
“The content was excellent and incredibly practical, diving deep into the art and science of forecasting. The unexpected highlight was the group itself. It was one of the most uniquely thoughtful, globally diverse rooms I’ve been part of in a long time. … Grateful for the experience and the brilliant people I met. Highly recommend it to anyone serious about sharpening their judgment or improving decision quality.”
— Jeff Trueman, Eisengard AI, November 2025
Although 2025 marked ten years since the publication of Tetlock and Gardner’s Superforecasting: The Art and Science of Prediction, forecasting as a discipline is still a novel way of thinking for many organizations. It feels risky to put a number on a prediction, because with numbers comes accountability. But accountability leads to better forecasting and hence better decisions. This case is getting easier to make, especially when we can point to years of Superforecasters’ documented outperformance of the competition, the markets and, now, the machines.
To our clients, staff, and forecasters: thank you. We wouldn’t be here without your energy, rigor, and recognition. Here’s to another year of proving what human judgment can do with the ever-evolving tools that we have.
 In October 2025, our colleagues at the Forecasting Research Institute released new ForecastBench
In October 2025, our colleagues at the Forecasting Research Institute released new ForecastBench 