One Question, Two Tariffs: How Polymarket’s Contract Design Dodged a Bullet
The prediction market bundled two distinct legal questions into one contract on Trump’s tariffs. The Court happened to treat them the same way. That was luck, not design, writes Ryan Adler, GJ Question Team Lead.

Years ago, I was in a city council meeting for a budget presentation. I had put together a number of tables and figures. In what is probably not a unique experience, I saw during the presentation that one of my tables had an underlying error for a key figure. There was a sum formula that excluded a line item that had been added later. To my relief, nobody noticed. Later, I updated the file so that the table was correct for future use, and went on with the knowledge that I dodged a bullet.
When you make a mistake in Excel, whether due to a typo when setting a range or outright negligence, you don’t have to worry too much about the mistake jumping off the screen or page for a large number of people (especially when the money involved is someone else’s). Event contract markets don’t have the luxury of innumeracy, because people are putting their own money forward and expecting a return.
I got lucky with my spreadsheet. If one were careful enough to notice, a similar scenario played out with Polymarket’s contract on whether the Supreme Court would rule in favor of Trump’s tariffs under the International Emergency Economic Powers Act (IEEPA). In the end, their oversight was immaterial to the outcome, but it could have been another unforced error (e.g., see my last post).
Splitting the Baby
At Good Judgment, I made a deliberate choice to split the issue into two questions. The first asked: “Before 1 August 2026, will the Supreme Court rule in Trump v. V.O.S. Selections Inc. that all of President Trump’s ‘reciprocal tariffs’ are either not authorized by the IEEPA or unconstitutional?” The second asked the same thing, but about the “trafficking tariffs.”
That distinction wasn’t cosmetic. The reciprocal tariffs and the trafficking tariffs arose from different executive orders and were justified by different facts and very different scopes. Yes, the cases were consolidated together. Yes, the Federal Circuit addressed them in the same opinion. But it was entirely plausible that the Supreme Court could have treated them differently. Courts are perfectly capable of splitting the baby.
Polymarket, by contrast, offered a single, bundled contract: “Will the Supreme Court rule in favor of Trump’s tariffs?” Their resolution criteria tied the outcome to whether the Court reversed or vacated the Federal Circuit’s holding that the tariffs exceeded IEEPA authority. Clean enough on paper, but it assumed that “the tariffs” were one thing. They were not.
If the Court had upheld the trafficking tariffs but struck down the reciprocal tariffs, or vice versa, my decision to split the question into two would have saved us, with one question resolving as “Yes” and the other “No.” Polymarket would have had to interpret whether the government had “prevailed.” That’s the kind of ambiguity you don’t want when people have money on the line.
(A note on “prevailed”: This is not a great term to use for a question/market. Anyone who reads a lot of federal appellate decisions, whether professionally or for fun, knows that litigation over what is meant by “prevailing party” has led to the deaths of many trees.)
Polymarket ducked a mess because the Court ultimately treated the categories the same way, but that was luck layered on top of legal reality.
The figure above shows how this played out in forecasting. Early on, our Superforecasters assigned different probabilities to the two questions. The reciprocal tariffs consistently carried a higher probability of being struck down than the trafficking tariffs. That divergence reflected genuine legal distinction, and Polymarket’s framing failed to account for it.
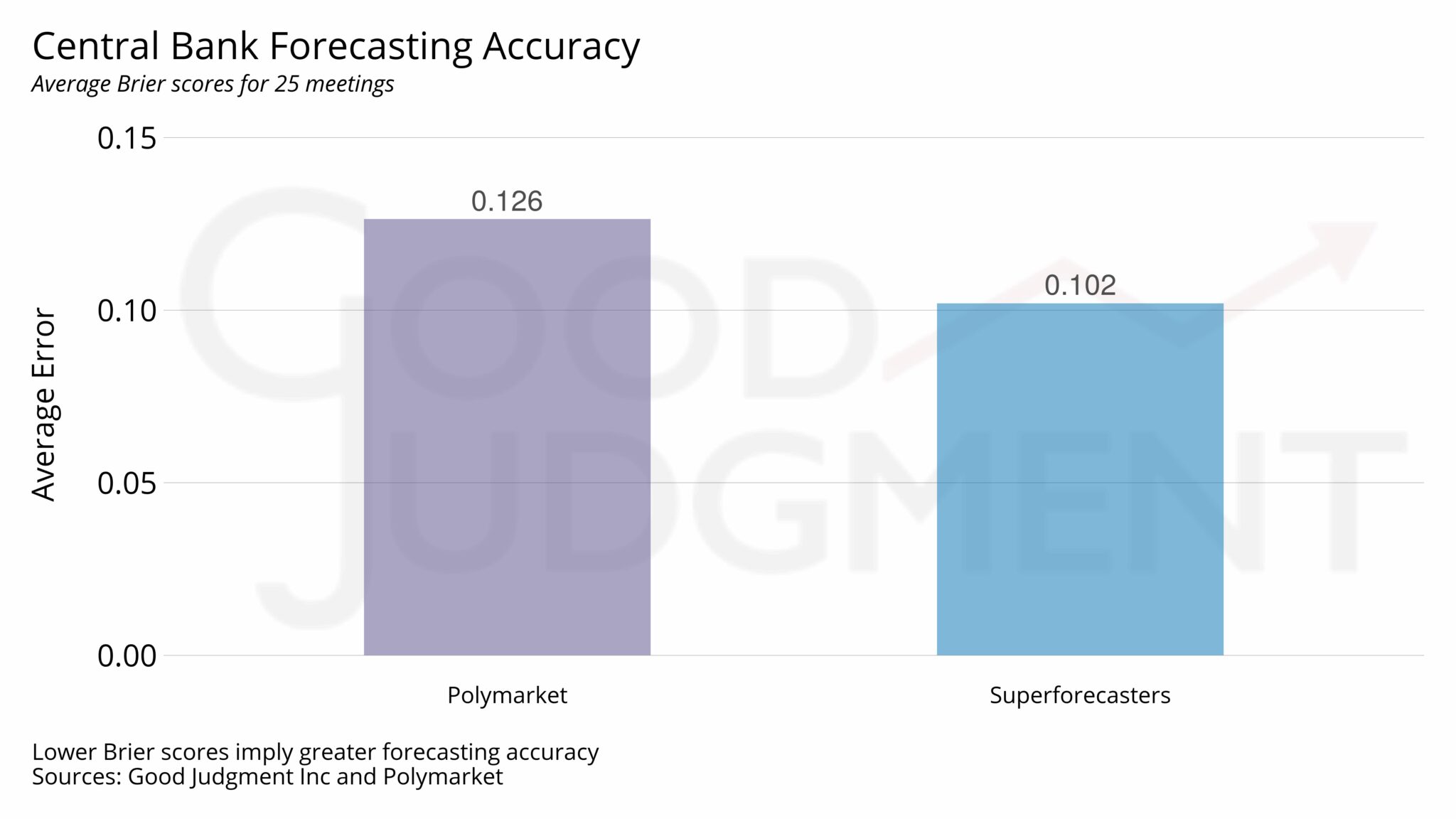
After oral arguments in early November gave insight as to where the Justices’ attention was focused, the two Good Judgment lines converged. By early February, Superforecasters were around 80 percent that the administration would lose on the reciprocal tariffs. Polymarket’s pricing implied something closer to the mid-70s. On 20 February, the Supreme Court ruled against the administration.
You can argue about who was a few percentage points closer. That’s not the interesting part. The interesting part is structural. Markets are only as clean as their definitions. When you bundle distinct legal questions into one contract, you are implicitly betting that the Court won’t differentiate. In this case, Polymarket dodged the bullet. But if the Court had drawn finer lines, as courts often do, the market could have faced a messy resolution.
I got to fix my spreadsheet after the meeting. A forecasting question or a prediction market needs to nail it the first time.
Keep up with the latest Superforecasts with a FutureFirst subscription.