What Superforecasters Actually Said About ForecastBench

Every few months, a new AI benchmark result gets journalists excited. Claims spike, the headlines write themselves, and nuance gets left behind.
Good Judgment welcomes AI progress on forecasting. We’ve argued consistently that the answer is Superforecasters plus AI, not one or the other. But the latest round of claims deserves a closer look, because the full report tells a very different story from the summary.
The Substack post
On 23 February 2026, the Forecasting Research Institute published Wave 5 of the Longitudinal Expert AI Panel (LEAP), a recurring survey tracking forecasts from AI scientists, industry leaders, economists, policy researchers, and Superforecasters. Alongside the report, FRI shared a Substack blog post summarizing the key findings.
Here’s what it says on ForecastBench*, in full:
AI systems are expected to surpass top human forecasters within the next few years, but the significance of that achievement is debated. Superforecasters themselves are the most bullish group on automated forecasting progress, with the median superforecaster predicting AI systems will beat their ForecastBench benchmark by 2028, which is earlier than both the median expert (2030) and the median public (2033) forecast.
*ForecastBench is a benchmark measuring AI systems’ forecasting accuracy against a 2024 Superforecaster baseline.
The report
The report’s topline summary of the same finding includes an additional passage that did not make it into the blog post:
However, forecasters qualitatively disagree on what this milestone would signify. Many note that AI excels at data-rich, quantitative questions (weather, sports, financial data) but struggles with geopolitical judgment where data is sparse and context-dependent. Others caution that because ForecastBench is structured as a frozen 2024 human baseline with many data-heavy questions and multiple AI attempts, this advantages AI systems in ways that may overstate genuine forecasting superiority.
The rationales
The report’s most interesting feature, the rationale analysis, goes further. Superforecasters were among those who most explicitly flagged that ForecastBench’s design makes an early AI “win” more likely for reasons that have little to do with genuine forecasting ability.
Their concerns:
- The Superforecaster baseline comes from a single engagement in 2024. AI systems are now scored on entirely different questions. ForecastBench uses difficulty-adjusted Brier scores to bridge that gap, but each layer of statistical bridging adds uncertainty to the comparison.
- Many questions focus on weather, sports, and financial data where AI has a structural advantage from data access rather than judgment.
- Multiple AI systems are tested every two weeks, meaning that, as one respondent put it, “given enough evaluations, eventually one will fall under this mark by chance.”
One participating Superforecaster stated directly that the score measures “how well an LLM can make good predictions in general, in comparison to the public and to generalists, rather than it being intended as a specific comparison to Superforecasters.”
In other words, many respondents who predicted a relatively early date for LLMs hitting the benchmark were simultaneously arguing that, in practice, it wouldn’t mean much. “Bullish” is not the word here.
In addition, as yet another participating Superforecaster wrote,
Beating the superforecaster median on ForecastBench after difficulty adjustment is a much higher bar than ‘be competitive.’ The last bit of improvement is going to be brutally hard for AI: excellent calibration, restraint (knowing when not to be confident), and robustness across lots of weird question types.
What this means
None of this is a criticism of ForecastBench as a research project. The benchmark is a serious attempt to measure something that matters, and the FRI team has been transparent about its methodology in the technical documents. But there is a gap between what the benchmark can show and what the headlines claim it shows.
Superforecasters still lead on the overall ForecastBench leaderboard, and on the “market questions,” they are almost 50% more accurate (0.40 vs. 0.59) than the nearest AI entrant. The questions resolved so far skew toward short-horizon, data-rich topics where AI has structural advantages. The longer-range, judgment-heavy questions are still pending. And as we’ve written before, the benchmark doesn’t capture teaming, advanced aggregation, updated forecasts, or the upstream work of formulating the right questions in the first place.
As Dr. Warren Hatch told the New York Times earlier this month: “When the data is sparse and the environment is in flux, machines are backward looking by definition. And that’s where I think the space for humans will remain.”
Good Judgment provides forecasts and analysis from our team of professional Superforecasters to government, NGO, and corporate decision-makers. Learn more about FutureFirst.
 It’s been a challenging year. Public imagination has been captured by prediction markets and AI alike as potential oracles for, well, everything. And yet, here we are at Good Judgment Inc, not just standing but setting records.
It’s been a challenging year. Public imagination has been captured by prediction markets and AI alike as potential oracles for, well, everything. And yet, here we are at Good Judgment Inc, not just standing but setting records.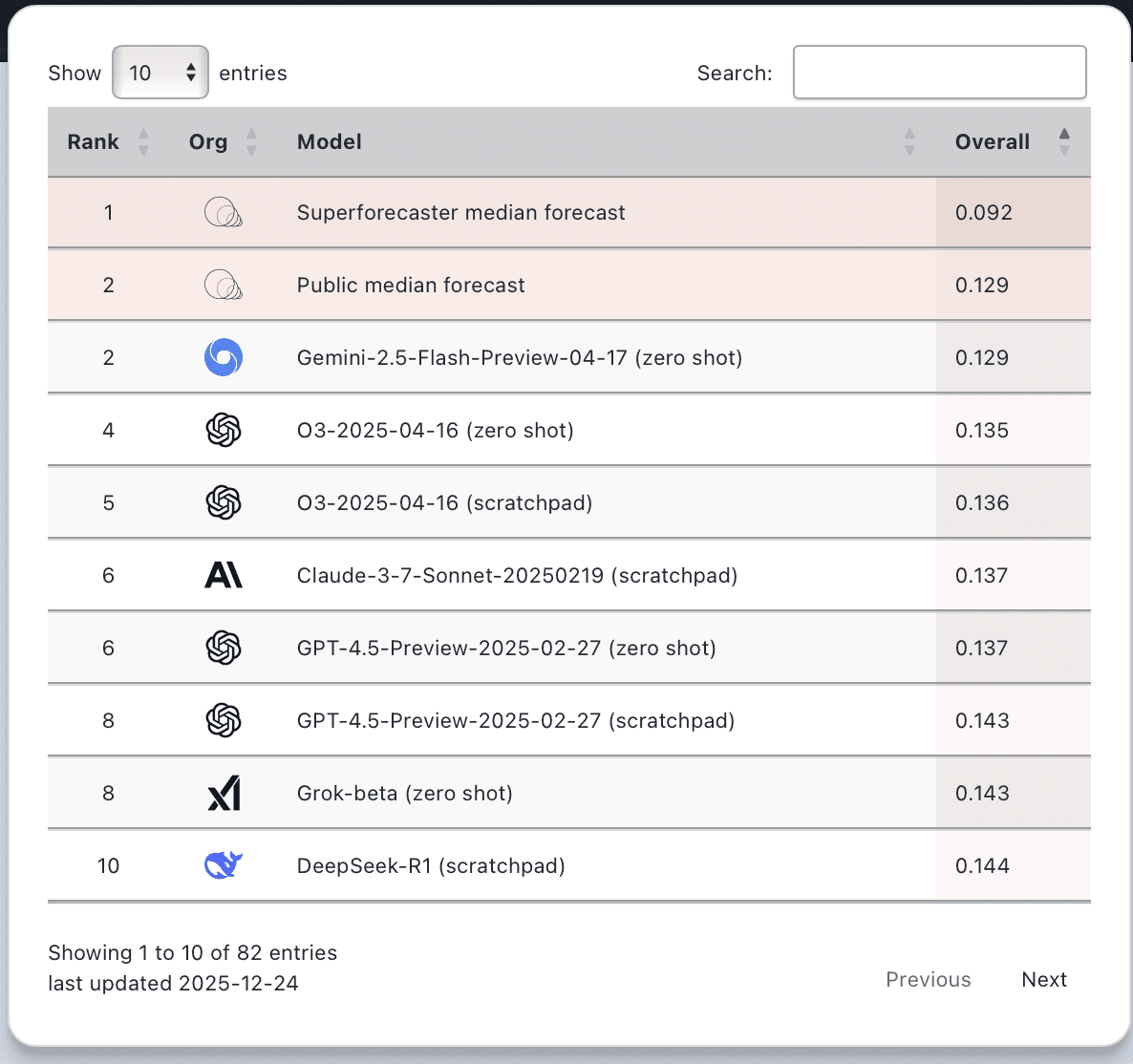
 In October 2025, our colleagues at the Forecasting Research Institute released new ForecastBench
In October 2025, our colleagues at the Forecasting Research Institute released new ForecastBench